Description
Gets a HSSP file of the requested structure.
Usage
get.hssp(file, path, keepfiles = TRUE)
Arguments
pdb the 4-letter identifier of the PDB file.
path character string providing the path to the in-house HSSP database.
keepfiles logical, if TRUE the dataframes will be saved in the working directory and we will keep the hssp file.
Value
Returns 4 dataframes containing the information found in hssp files, as describe below.
References
Touw et al (2015) Nucl. Ac. Res. 43:D364-368.
Lange et al (2020) Protein Sci. 29:330-344.
See Also
msa(), custom.aln(), list.hom(), parse.hssp(), shannon(), site.type()
Details
Multiple sequence alignment (MSA), which consists in the alignment of three or more biological sequences. From the output, homology can be inferred and the evolutionary relationships between the sequences studied. Thus, alignment is the most important stage in most evolutionary analyses. In addition, MSA is also an essential tool for protein structure and function prediction. The package ptm offers several functions that will assist you in the process of sequence analysis:
msa
custom.aln
list.hom
parse.hssp
get.hssp (current doc)
shannon
site.type
The function get.hssp() will obtain and parse the requested HSSP file. HSSP stands for Homology-derived Secondary Structure of Proteins. These files contain information related to MSAs of UniProtKB against PDB. When the argument ‘keepfiles’ is set to TRUE, the get.hssp() function will build and save (in the working directory) the following 4 dataframes:
-
id_seq_list.Rda: This block of information holds the metadata per sequence, and some alignment statistics. For a detailed description of the information that can be find in this block, check here.
-
id_aln.Rda: This dataframe contains the alignment itself (each sequence is a column). Additional information such as secondary structure, SASA (solvent accessible surface area), etc is also found in this block.
-
id_profile.Rda: This dataframe holds per amino acid type its percentage in the list of residues observed at the indicated position. In addition, this dataframe also informs about the entropy at each position, as well as the number of sequences spanning this position (NOOC).
-
id_insertions.Rda: A dataframe with information regarding those sequences that contain insertions. Click here for further details.
In order to use this function, you need to obtain a local copy of the HSSB database. This is a process that can take a few minutes, but it only have to be done once. To do that, you can follow the indication given here. I have created my copy of HSSB in a folder whose absolute path is ‘/Users/juancarlosaledo/ptm_outdropbox/local_HSSP/’, so to obtain the hssp information related to the PDB structure 1U8F, all I have to type in R is:
profile <- get.hssp(pdb = '1u8f',
path = "/Users/juancarlosaledo/ptm_outdropbox/local_HSSP/",
keepfiles = TRUE)
The object ‘profile’ is a dataframe with as many rows as residues has the protein. For each position, the following variables (columns) are shown:
- SeqNo: Sequence residue number.
- PDBNo: PDB residue number.
- V: Percentage at which the amino acid valine (Val) is found at that position.
- L: Percentage at which the amino acid leucine (Leu) is found at that position.
- I: Percentage at which the amino acid Isoleucine (Ile) is found at that position.
- M: Percentage at which the amino acid methionine (Met) is found at that position.
- F: Percentage at which the amino acid phenylalanine (Phe) is found at that position.
- W: Percentage at which the amino acid tryptopha (Trp) is found at that position.
- Y: Percentage at which the amino acid tyrosine (Tyr) is found at that position.
- A: Percentage at which the amino acid alanine (Ala) is found at that position.
- G: Percentage at which the amino acid glycine (Gly) is found at that position.
- P: Percentage at which the amino acid proline (Pro) is found at that position.
- S: Percentage at which the amino acid serine (Ser) is found at that position.
- T: Percentage at which the amino acid threonine (Thr) is found at that position.
- C: Percentage at which the amino acid cysteine (Cys) is found at that position.
- Q: Percentage at which the amino acid glutamine (Gln) is found at that position.
- N: Percentage at which the amino acid asparragine (Asn) is found at that position.
- H: Percentage at which the amino acid histidine (His) is found at that position.
- R: Percentage at which the amino acid arginine (Arg) is found at that position.
- K: Percentage at which the amino acid lysine (Lys) is found at that position.
- E: Percentage at which the amino acid glutamate (Glu) is found at that position.
- D: Percentage at which the amino acid aspartate (Asp) is found at that position.
- NOCC: Number of aligned sequences spanning this position (including the test sequence).
- NDEL: Number of sequences with a deletion in the test protein at this position.
- NINS: Number of sequences with an insertion in the test protein at this position.
- ENTROPY: Entropy measure of sequence variaparbility at this position.
- RELENT: Relative entropy, i.e. entropy normalized to the range 0-100.
- WEIGHT: Conservation weight.
We can have a visual impression of which are the most variable and the most conserved positions by plotting the relative entropy as a function of the position:
plot(profile$SeqNo, profile$RELENT, ty = 'h', xlab = 'Position', ylab = 'Relative Entropy')
In this way, the most variable position is:
maxS_at <- which(profile$ENTROPY == max(profile$ENTROPY))
x <- as.data.frame(t(profile[maxS_at, 3:22]))
x$col <- c(rep("orange", 8), rep("purple", 2), rep("green", 5), rep("blue", 3), rep("red",2))
names(x) <- c('frequency', 'col')
barplot(height = x$frequency,
names = rownames(x),
col = x$col,
main = paste("Position:", profile$PDBNo[maxS_at]))
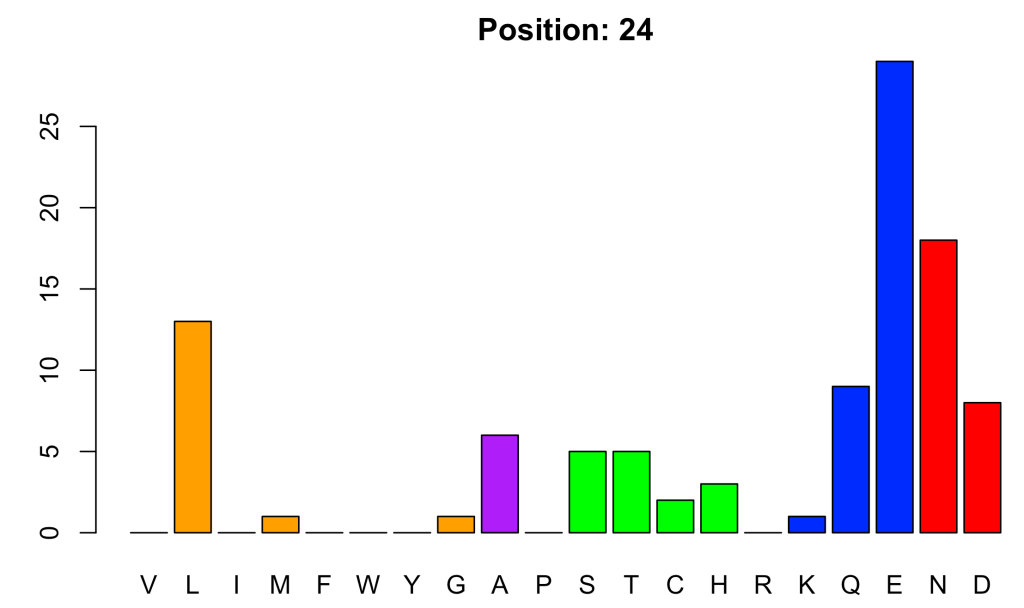
Here, we have colored the amino acids according to their physicochemical nature. Acidic (E, D) in red, basic (H, R, K) in blue, hydrophobic (L, I, M, F, W, Y, A) in orange, polar (S, T, C, Q, N) in green and special (G, P) in purple.
In contrast, the most conserved position is:
minS_at <- which(profile$ENTROPY == min(profile$ENTROPY))
x <- as.data.frame(t(profile[minS_at, 3:22]))
x$col <- c(rep("orange", 8), rep("purple", 2), rep("green", 5), rep("blue", 3), rep("red",2))
names(x) <- c('frequency', 'col')
barplot(height = x$frequency,
names = rownames(x),
col = x$col,
main = paste("Position:", profile$PDBNo[minS_at]))

where valine is the only amino acid present!
In addition to this dataframe we have colled ‘profile’, we can access, if we wish, the alignment itself:
load("./1u8f_aln.Rda")
dim(aln)
## [1] 333 528
This dataframe, that we have placed in an object colled ‘aln’, has 333 raws (one per residue) and 528 columns. The first eight colums are:
- SeqNo: Sequence residue number.
- PDBNo: PDB residue number.
- Chain: Chain identifier.
- AA: Amino Acid at that position in the reference sequence.
- SS: Element of secondary structure.
- ACC: Solven accessible area.
- NOCC: Number of aligned sequences spanning this position (including the reference sequence).
- VAR: Sequence variability on a scale of 0-100 as derived from the number of sequences aligned.
The ninth column (named in this example ‘P04406’) gives the reference sequence, while the remaining colums provide the sequence of the protein included in the alignment. These columns are named with the UniProt ID of the corresponding protein.
Information regarding the metadata per sequence, and some alignment statistic, can be found in a third dataframe:
load("./1u8f_seq_list.Rda")
head(seq_list)
## NR ID IDE WSIM IFIR ILAS JFIR JLAS LALI NGAP LGAP LESEQ2 ACCNUM ## 1 1 G3P_HUMAN 1.00 1 1 333 3 335 333 0 0 335 P04406 ## 2 2 G3R288_GORGO 1.00 1 1 333 3 335 333 0 0 335 G3R288 ## 3 3 H2Q5A6_PANTR 1.00 1 1 333 3 335 333 0 0 335 H2Q5A6 ## 4 4 V9HVZ4_HUMAN 1.00 1 1 333 3 335 333 0 0 335 V9HVZ4 ## 5 5 A0A096MS12_P 0.99 1 1 333 3 335 333 0 0 335 A0A096MS12 ## 6 6 A0A0A7KUP9_M 0.99 1 1 333 3 335 333 0 0 335 A0A0A7KUP9 ## PROTEIN ## 1 Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=GAPDH PE=1 SV=3 ## 2 Glyceraldehyde-3-phosphate dehydrogenase OS=Gorilla gorilla gorilla GN=GAPDH PE=3 SV=1 ## 3 Glyceraldehyde-3-phosphate dehydrogenase OS=Pan troglodytes GN=GAPDH PE=3 SV=1 ## 4 Glyceraldehyde-3-phosphate dehydrogenase OS=Homo sapiens GN=HEL-S-162eP PE=2 SV=1 ## 5 Glyceraldehyde-3-phosphate dehydrogenase OS=Papio anubis PE=3 SV=1 ## 6 Glyceraldehyde-3-phosphate dehydrogenase OS=Macaca fascicularis GN=GAPDH PE=2 SV=1
The number of rows, in our example, is 520 (one per sequence included in the alignment). The variables (columns) holded in this dataframe are:
- NR: Sequence number.
- ID: EMBL/SWISSPROT identifier of the aligned (homologous) protein.
- IDE: Percentage of residue identity of the alignment.
- WSIM: Weighted similarity of the alignment.
- IFIR: First residue of the alignment in the test sequence.
- ILAS: Last residue of the alignment in the test sequence.
- JFIR: First residue of the alignment in the alignend protein.
- JLAS: Last residue of the alignment in the alignend protein.
- LALI: Length of the alignment excluding insertions and deletions.
- NGAP: Number of insertions and deletions in the alignment.
- LGAP: Total length of all insertions and deletions.
- LSEQ2: Length of the entire sequence of the aligned protein.
- ACCNUM: SwissProt accession number.
- PROTEIN: One-line description of aligned protein.
Finally, a fourth dataframe, named ‘insertions’ can be assessed
load("./1u8f_insertions.Rda")
inser
## AliNo IPOS JPOS Len Sequence
## 1 72 235 221 2 pTPt
## 2 73 297 297 5 gAGIAGa
## 3 77 175 177 3 nWLLp
## 4 77 189 194 3 gTGSp
## 5 78 289 286 1 tQh
## 6 90 23 54 1 sGc
## 7 112 27 27 1 gVe
## 8 113 27 27 1 gVe
## 9 119 23 23 2 sSAs
## 10 123 27 27 1 gVe
## 11 126 41 41 3 yMAMl
## 12 127 27 26 1 vVe
## 13 130 229 218 2 gMAt
## 14 137 56 56 1 kLg
## 15 138 56 75 1 kLg
## 16 139 27 27 1 gVe
## 17 141 23 23 2 sSAs
## 18 143 133 128 18 gVNQDKYDNSLKIVSNVMGv
## 19 146 263 248 1 rRr
## 20 149 56 56 1 kHs
## 21 150 27 25 1 gAe
## 22 152 192 196 15 gKLCITCSRRWGYSVSl
## 23 152 245 264 4 sCHLTc
## 24 154 56 56 1 kHg
## 25 157 27 25 1 gGd
## 26 159 263 268 1 aSa
## 27 160 27 17 1 gAk
## 28 161 27 17 1 gAk
## 29 162 27 25 1 gAq
## 30 163 27 51 1 gAt
## 31 165 27 25 1 gAq
## 32 167 289 256 2 pPAh
## 33 168 142 141 1 aSm
## 34 171 27 25 1 gAq
## 35 172 27 25 1 gAk
## 36 173 276 268 1 tTd
## 37 173 307 300 1 sLk
## 38 174 41 40 1 yIl
## 39 175 27 25 1 gAq
## 40 176 27 25 1 gGq
## 41 177 27 25 1 gAq
## 42 178 27 25 1 gAq
## 43 179 27 27 1 gAq
## 44 180 27 51 1 gAt
## 45 181 27 51 1 gAt
## 46 182 27 51 1 gAt
## 47 183 27 51 1 gAt
## 48 184 27 51 1 gAt
## 49 185 27 51 1 gAt
## 50 186 27 51 1 gAt
## 51 187 27 51 1 gAt
## 52 188 23 23 2 eRGg
## 53 188 24 26 1 gQv
## 54 188 27 30 1 vNq
## 55 189 27 25 1 gAq
## 56 190 27 55 1 gGq
## 57 191 27 25 1 gGq
## 58 192 27 32 1 gGq
## 59 193 27 53 1 gGq
## 60 194 27 25 1 gAq
## 61 195 27 25 1 gAn
## 62 196 27 25 1 gAn
## 63 197 27 25 1 gAs
## 64 198 27 25 1 gAn
## 65 199 27 25 1 gAq
## 66 200 23 26 1 eKg
## 67 201 27 25 1 gGq
## 68 202 27 25 1 gGq
## 69 203 69 71 5 tKDGKSq
## 70 203 142 149 1 aNd
## 71 204 27 25 1 gAq
## 72 205 27 25 1 gAt
## 73 207 69 71 5 tKDGKTq
## 74 207 142 149 1 aNd
## 75 208 27 25 1 gAq
## 76 209 27 25 1 gAq
## 77 210 27 25 1 gAq
## 78 211 27 25 1 gAq
## 79 212 27 25 1 gAt
## 80 213 27 25 1 gAq
## 81 214 27 25 1 gAt
## 82 215 27 27 1 gIk
## 83 215 142 143 1 sSm
## 84 216 27 25 1 gAq
## 85 217 27 25 1 gAq
## 86 218 263 264 1 aAs
## 87 219 27 28 1 gGt
## 88 220 27 25 1 gVe
## 89 220 263 262 1 aAa
## 90 221 27 25 1 gAq
## 91 222 27 51 1 gAt
## 92 223 23 24 1 aLn
## 93 223 263 264 1 kAs
## 94 224 263 264 1 aAs
## 95 225 27 25 1 gAq
## 96 226 27 25 1 gVe
## 97 226 263 262 1 aAa
## 98 227 27 25 1 gAs
## 99 228 27 25 1 gAs
## 100 229 27 25 1 gAe
## 101 230 27 25 1 gAq
## 102 231 27 25 1 gAn
## 103 232 27 25 1 gAs
## 104 233 27 25 1 gAn
## 105 234 27 25 1 gAn
## 106 235 27 25 1 gAn
## 107 236 27 25 1 gAq
## 108 237 27 27 1 gIk
## 109 237 142 143 1 sSm
## 110 238 27 25 1 gVe
## 111 238 263 262 1 aAa
## 112 239 27 25 1 gGq
## 113 240 69 71 5 tKEGKSq
## 114 240 142 149 1 aNd
## 115 241 18 18 1 tSr
## 116 242 27 27 1 gIk
## 117 242 142 143 1 sSm
## 118 243 69 71 5 aNEGKSq
## 119 243 142 149 1 aNd
## 120 244 27 25 1 gAs
## 121 245 27 25 1 gAe
## 122 246 27 25 1 gAq
## 123 247 27 25 1 gAq
## 124 248 27 25 1 gAq
## 125 250 27 25 1 gAn
## 126 251 27 25 1 gAs
## 127 252 27 27 1 gIk
## 128 252 142 143 1 sSm
## 129 253 27 27 1 gIk
## 130 253 142 143 1 sSm
## 131 254 27 27 1 gIk
## 132 254 142 143 1 sSm
## 133 255 27 25 1 gVe
## 134 255 263 262 1 aAa
## 135 256 27 25 1 gVd
## 136 256 263 262 1 aAa
## 137 257 27 25 1 gAq
## 138 258 27 25 1 gAs
## 139 259 27 27 1 gIk
## 140 259 142 143 1 sSm
## 141 260 263 264 1 aAs
## 142 261 27 25 1 gAq
## 143 262 27 25 1 gAe
## 144 265 69 71 5 kQDGKDt
## 145 265 142 149 1 aNd
## 146 266 27 42 1 gAe
## 147 267 69 77 5 sKEGKSt
## 148 267 142 155 1 aNn
## 149 268 27 38 1 gIk
## 150 268 142 154 1 sSm
## 151 269 27 25 1 gAs
## 152 270 27 25 1 gAq
## 153 271 27 25 1 gAq
## 154 272 27 25 1 gAs
## 155 273 27 25 1 gAq
## 156 274 69 71 4 sFGGSt
## 157 274 142 148 1 nTn
## 158 275 27 25 1 gGq
## 159 276 263 277 1 aAa
## 160 277 27 25 1 gAn
## 161 278 113 115 1 nDr
## 162 279 113 115 1 nDr
## 163 280 113 115 1 nDr
## 164 281 113 115 1 nDr
## 165 282 113 115 1 nDr
## 166 283 113 115 1 nDr
## 167 284 113 115 1 nDr
## 168 285 113 115 1 nDr
## 169 286 113 115 1 nDr
## 170 287 113 115 1 nDr
## 171 288 113 115 1 nDr
## 172 289 23 19 2 sSAs
## 173 289 200 185 1 gGa
## 174 290 189 188 2 gSYv
## 175 292 27 27 1 gIk
## 176 292 142 143 1 sSm
## 177 294 23 24 1 lNp
## 178 295 27 27 1 gIk
## 179 295 142 143 1 sSm
## 180 296 113 115 1 nDr
## 181 297 113 115 1 nDr
## 182 298 263 264 1 aAs
## 183 299 69 71 5 sLDGKSt
## 184 299 142 149 1 aNn
## 185 299 235 243 2 rVPt
## 186 300 189 149 1 gWp
## 187 301 69 71 5 kQDGKDa
## 188 301 142 149 1 aNd
## 189 302 142 142 1 tKh
## 190 303 23 24 1 dNp
## 191 303 263 264 1 kAs
## 192 304 23 24 1 dNp
## 193 304 263 264 1 kAs
## 194 305 69 71 5 gLDGKSt
## 195 305 142 149 1 aNn
## 196 306 23 24 1 aNp
## 197 307 23 23 1 qLp
## 198 308 69 71 4 tNGKTt
## 199 308 142 148 1 aNn
## 200 309 69 71 5 kQDGKDp
## [ reached 'max' / getOption("max.print") -- omitted 337 rows ]
Further details regarding the information provided by this dataframe can be obtained here.
Please, mind that if the argument ‘keepfiles’ is set to FALSE, only the dataframe ‘profile’ will be returned, and the hssp file will be delated from you machine.
